
I was recently at SMX London where I delivered a talk called "Search + UX: The Behavioural Data Your SEO Strategy Should Care About".

I spoke about all of those behavioural metrics that we SEOs have been leaving behind as they're not 'official ranking factors', and all of the diagnostic tools you can use to figure out UX improvement opportunities that can benefit search, too.
Among the underrated data I spoke about, there were those coming from customer surveys, customer experience/customer service logs, reviews and online forums.
What's so good about customer data for SEO?
Organic content coming directly from a customer (or a prospect) can unlock friction points and blockers that might be hard to identify only with only quantitative data from WebAnalytics or any of the usual SEO tools.
Some of the common friction points can be, for example:
Shipping, delivery and return policy
Legitimacy of the brand
Website errors and poor UX
But can extend to a number of other topics that might be challenging to analyse at scale.

When you're familiar with a brand and their process, it's easy to assume that someone else's experience and point of view will be similar to yours. But biases, motivations and previous experiences shape behaviours differently, so it's important that the quantitative data we obtain from analytics to tell us what is happening (e.g. drop in clicks, low check-out rates) can be paired with the qualitative data that can tell us why that is happening.
How can I get qualitative data directly from my customers or prospects - and what do I do with it?
To get this kind of behavioural data, you can either:
Speak to your customer support agents and ask about some of the most common topics that come up
Actively run pre or post-purchase surveys (e.g. 'What almost stopped you from buying today?' after check-out)
Scrape reviews, social mentions and online forums to capture both customers' frustrations and pre-purchase blockers encountered by prospects.
We're going to see this last option below, since it's one of the things I tested for my talk and it's easily scalable.
How to scrape brand reviews with Python on Colab
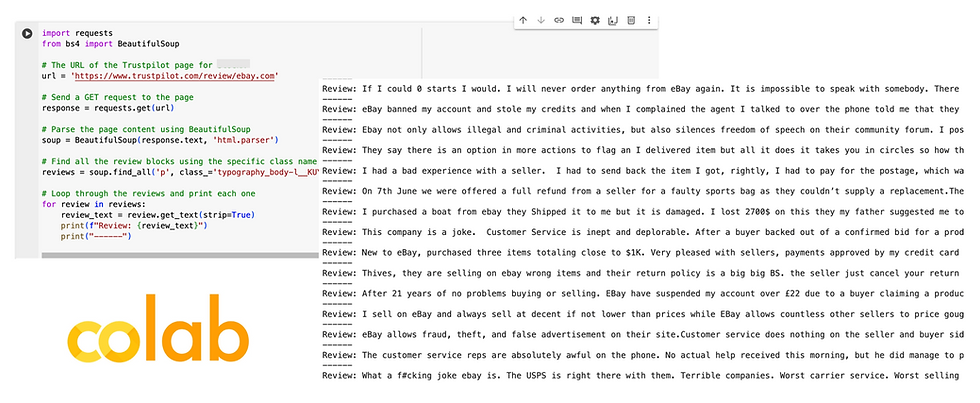
The first step is to identify the brand and the reviews site you want to scrape.
For example, I ran this exercise for Ebay on Trustpilot.
Bear in mind that there might be some blockers on the specific reviews site, so you might have to work around those limitations.
The second step is to open Colab (free and open source Google tool that allows you to write and execute Python in your browser).
If that's your first time using it, all you have to do to get started is click on that 'Code' box on the top left, and input what comes in the next section.
You will first need to install and import the framework and libraries needed for this project, Webdriver (this allows you to perform automated tasks across browsers), BeautifulSoup (your HTML parser needed to scrape) and Pandas (to analyse and manipulate data).
Input the commands below in the grey coding area to do so:
!pip install selenium
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import pandas as pdThen press the 'Play' button on the left of the cell to run it:

You can then move on to the actual scraping task, following this template I used:
import requests
from bs4 import BeautifulSoup
# The URL of the Trustpilot page for Ebay
url = 'https://www.trustpilot.com/review/ebay.com'
# Send a GET request to the page
response = requests.get(url)
# Parse the page content using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Find all the review blocks using the specific class name from the HTML *
reviews = soup.find_all('p', class_='typography_body-l__KUYFJ typography_appearance-default__AAY17 typography_color-black__5LYEn')
# Loop through the reviews and print each one
for review in reviews:
review_text = review.get_text(strip=True)
print(f"Review: {review_text}")
print("------")*Note that this might need to change if you use a different website than Trustpilot. You will need to go into Inspect Mode and find the HTML class that specifies your reviews section, and input that code in place of 'typography_body-l__KUYFJ typography_appearance-default__AAY17 typography_color-black__5LYEn'.
And voila! You have your set of reviews.

A note for paginated websites:
The script above will give you anything that is included in the URL of choice, but if the reviews expand over a set of paginated URLs, you will need extra steps to define the new pages to analyse.
Below is the extended script to include the paginated URLs on top of the base one (again, this is for Trustpilot specific example, and you might need to tweak rules based on the URL structure of the website you choose to scrape):
import requests
from bs4 import BeautifulSoup
base_url = "https://www.trustpilot.com/review/ebay.com"
max_pages = 10
# Scrape the first page (without the "?page=" parameter)
urls = [base_url]
# Add URLs for subsequent pages with "?page=" parameter
for page_num in range(1, max_pages + 1):
urls.append(f"{base_url}?page={page_num}")
# Iterate through all URLs (including the first page)
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Find all reviews on the current page (this is retained from the previous script)
reviews = soup.find_all('p', class_='typography_body-l__KUYFJ typography_appearance-default__AAY17 typography_color-black__5LYEn')
# Loop through the reviews on the current page and print each one
for review in reviews:
review_text = review.get_text(strip=True)
print(f"Review: {review_text}")
print("------")
print(f"Review: {review_text}")
print("------")
This will bring back significantly more reviews that you can analyse in the next step.
What do I do now with all this data?
You have three options:
You can use a free tool to analyse Ngrams like Voyant-Tools to give you a full overview of the most used terms, their relationships and their connotation in context (negative VS positive).

You can use OpenAI or any other LLMs to help you identify common topics:

Or, you can work on another Python script to proceed in Colab!
Here is one based on the code and output above, that will give you the top topics and the suggested actions to address future customer concerns based on previous complaints proactively.
Buckle up because it's a long one, as it includes the specification for suggested actions.
# Import necessary libraries: if you have BeautifulSoup from the previous script already, you can skip row 2
import requests
from bs4 import BeautifulSoup
from gensim import corpora, models
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import string
# Download NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
# Define URL and scrape reviews (this is included in the previous script, so you might skip to the pre-process step if you want)
url = 'https://www.trustpilot.com/review/ebay.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
reviews = soup.find_all('p', class_='typography_body-l__KUYFJ typography_appearance-default__AAY17 typography_color-black__5LYEn')
# Preprocess reviews to create a list of lists (documents)
review_texts = [
[
word.lower() for word in word_tokenize(review.get_text(strip=True))
if word not in stopwords.words('english') and word not in string.punctuation
]
for review in reviews # Iterate through each review element
]
# Create dictionary, corpus, and LDA model
dictionary = corpora.Dictionary(review_texts)
# Pass the list of lists
corpus = [dictionary.doc2bow(text) for text in review_texts]
num_topics = 5
lda_model = models.LdaModel(corpus, id2word=dictionary, num_topics=num_topics)
# Print most common topics
print("Top common topics:")
for idx, topic in lda_model.print_topics(num_words=10):
print(f"Topic {idx+1}:")
print(topic)
# Suggest opportunities based on topic keywords
def suggest_opportunities(topic_keywords):
# Prioritize specific keyword combinations for more accurate suggestions (this can be tweaked based on most common topics and business model)
if any(word in topic_keywords for word in ["fake", "counterfeit", "scam"]):
if "item" in topic_keywords or "product" in topic_keywords:
return "Investigate potential product quality or authenticity issues."
else:
return "Strengthen measures to combat counterfeit products and protect buyers."
elif any(word in topic_keywords for word in ["money", "payment", "price", "cost", "fee"]):
if any(word in topic_keywords for word in ["refund", "dispute"]):
return "Investigate issues with refunds, disputes, or pricing concerns."
else:
return "Review pricing strategies and payment options to address potential customer concerns."
elif any(word in topic_keywords for word in ["shipping", "delivery", "delay", "late"]):
if "time" in topic_keywords:
return "Focus on reducing wait times for shipping or delivery."
else:
return "Focus on improving shipping times and tracking visibility."
elif any(word in topic_keywords for word in ["return", "refund", "policy"]):
return "Streamline the returns process and make it more customer-friendly."
elif any(word in topic_keywords for word in ["customer", "service", "support"]):
return "Enhance customer support channels and empower representatives to resolve issues quickly."
elif any(word in topic_keywords for word in ["seller", "communication"]):
return "Encourage better communication between buyers and sellers."
else:
return "Further investigation and data analysis needed."
# Print opportunities for each topic
for idx, topic in lda_model.print_topics(num_words=10):
print(f"Topic {idx+1}: {topic}")
print(f"Opportunity: {suggest_opportunities(topic)}")
print("------")Here is what this script gave me as top three actionable insights that I can bring into my hypothetical strategy for Ebay to remove friction and resolve painpoints:
Streamline return process and make it more customer-friendly
Encourage better communication between buyers and sellers
Enhance customer support channels and empower representatatives to resolve issues quickly.

From an SEO perspective, this doesn't immediately tell me specific actions, but it identifies areas to work on, for example:
Making sure return schema is enabled and that the return policy is clearly marked on the Merchant Centre; also, building FAQs and help pages directly related to returns to address any policies and concerns proactively
Making customer support channels more visible on the page and easy to interact with
Enable Q&A on product pages to facilitate communication between parties in the marketplace space.
From this, you can explore more actionable items that align directly with your team and your business goals, and find areas of cross-functional collaboration that might even result in a feature request.
Final note: Remember that by nature, Trustpilot tends to capture more of the post-purchase funnel, but you can repeat the same process on Reddit or other platforms to figure out how to improve some of the issues that might be arising before conversion and blocking it.
Are you going to give it a go?
Do you want to see the entire presentation at your conference? Contact me below ⬇️
And if you liked this article, please consider sharing it with your network!
Comments